Lokale KI mit Ollama und Gemma 4
Sichere KI-Nutzung für Unternehmen mit Datenschutzanforderungen
Autor: Christian Drapatz
Disclaimer
Diese Anleitung wurde auf Basis öffentlich zugänglicher Quellen eigenständig erstellt und in eigenen Worten auf Deutsch formuliert. Als primäre Quellen dienten die offizielle Ollama-Dokumentation (ollama.com, MIT-Lizenz), die offizielle OpenCode-Dokumentation (opencode.ai, MIT-Lizenz) sowie eigene Tests und Community-Beiträge. Gemma 4 wird von Google unter den Gemma Terms of Use veröffentlicht (kein MIT). Weitere genannte Modelle (Llama, Mistral, Qwen, DeepSeek, Phi) unterliegen den jeweiligen Lizenzbedingungen ihrer Hersteller. Die bereitgestellten Inhalte dienen ausschließlich der Wissensvermittlung. Es wird keine Gewähr für Vollständigkeit oder Aktualität übernommen. Alle genannten Marken, Produkte und Technologien gehören den jeweiligen Inhabern.
1 Warum lokale KI?
Viele Firmen möchten KI in ihren Entwicklungsprozess einbinden, stehen dabei aber vor einem grundsätzlichen Problem: Sensible Daten dürfen das eigene Netzwerk nicht verlassen.
Typische Beispiele:
- Quellcode mit Betriebsgeheimnissen
- Crash-Logs mit internen Stack Traces
- Interne Systemdokumentation
- Kundendaten oder personenbezogene Informationen
- Medizinische oder rechtliche Inhalte
Cloud-basierte KI-Dienste wie OpenAI, Anthropic oder Google senden Anfragen an externe Rechenzentren. Abhängig vom Anbieter können diese Rechenzentren außerhalb Deutschlands oder der EU liegen.
Lokale KI löst dieses Problem, indem das KI-Modell direkt auf dem eigenen Rechner oder im internen Firmennetzwerk läuft. Daten verlassen dabei die eigene Infrastruktur nicht.
Das macht lokale KI besonders interessant für:
- Versicherungen, Banken und Finanzdienstleister
- Gesundheitswesen und Krankenkassen
- Behörden und öffentliche Einrichtungen
- Industrieunternehmen mit sensiblen Fertigungsdaten
- Softwarefirmen mit strenger IP-Schutzanforderung
Wichtiger Vorbehalt: Lokale KI ist kein Allheilmittel für Datenschutz. Sie verschiebt die Kontrolle auf die eigene Infrastruktur – setzt aber weiterhin sorgfältige Konfiguration, Zugriffsrechte und Netzwerksicherheit voraus.
2 Grundlegende Architektur
Bevor man konkrete Werkzeuge einrichtet, hilft ein Überblick über die Schichten des Systems.
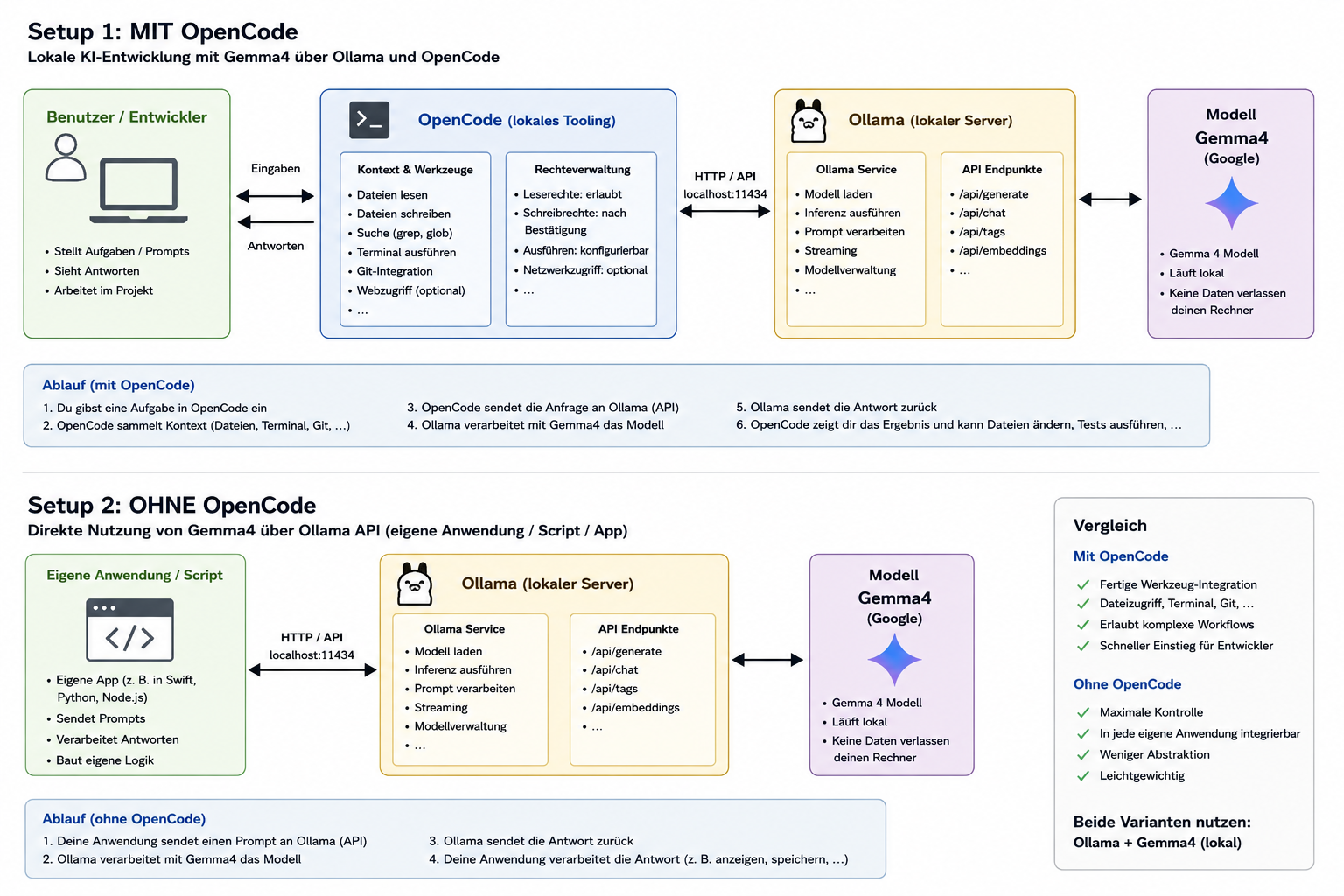
Systemarchitektur: Ollama mit Gemma 4
| Schicht | Aufgabe |
|---|---|
| KI-Modell | Verarbeitet den Prompt und erzeugt eine Antwort |
| Ollama | Lädt, verwaltet und startet Modelle; stellt die HTTP-API bereit |
| Eigene Anwendung | Baut Prompts, sendet Anfragen, verarbeitet Antworten |
| OpenCode (optional) | Tool-System, das Dateien liest, ändert und Befehle ausführt |
Hinweis: OpenCode und andere Tool-Systeme sind optional. Man kann Ollama direkt über HTTP ansprechen, ohne ein solches Tool-System zu verwenden.
3 Ollama
Ollama ist eine lokale Laufzeitumgebung für KI-Sprachmodelle. Es übernimmt das Laden, Verwalten und Ausführen von Modellen auf dem eigenen Rechner und stellt eine HTTP-Schnittstelle bereit, über die beliebige Anwendungen mit dem Modell kommunizieren können.
Ollama ist quelloffen und kostenlos. Es läuft als lokaler Dienst und ist für macOS, Linux und Windows verfügbar.
Was Ollama konkret tut:
- Modelle herunterladen und lokal speichern
- Modelle starten und Speicher verwalten
- Eine lokale HTTP-API auf Port 11434 bereitstellen
- Mehrere Modelle verwalten und bei Bedarf wechseln
- Eine OpenAI-kompatible API-Schnittstelle anbieten
3.1 Installation auf macOS
Voraussetzung: Homebrew. Falls noch nicht vorhanden:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/homebrew/install/HEAD/install.sh)"Wichtig auf Apple Silicon (M1/M2/M3/M4): Nach der Homebrew-Installation den PATH setzen:
# zsh
echo 'eval "$(/opt/homebrew/bin/brew shellenv)"' >> ~/.zprofile
source ~/.zprofile
# bash
echo 'eval "$(/opt/homebrew/bin/brew shellenv)"' >> ~/.bash_profile
source ~/.bash_profileDanach Ollama installieren:
brew install ollama
ollama --versionOllama als Hintergrunddienst starten (empfohlen):
brew services start ollama
# Status prüfen
brew services list | grep ollama
# Dienst stoppen
brew services stop ollamaAlternativ manuell im Vordergrund starten:
ollama serveServer-Erreichbarkeit prüfen:
curl http://localhost:11434
# Antwort: Ollama is running3.2 Modelle installieren
Der Server muss laufen, bevor Modelle installiert oder genutzt werden können.
# Gemma 4 installieren
ollama pull gemma4
# Spezifische Größe (sofern verfügbar)
ollama pull gemma4:27b
# Installierte Modelle anzeigen
ollama list
# Modell interaktiv testen
ollama run gemma4
# Modell entfernen
ollama rm gemma4Konfiguration über Umgebungsvariablen:
| Variable | Bedeutung |
|---|---|
OLLAMA_HOST | Bindet den Server an eine bestimmte Adresse (Standard: 127.0.0.1:11434) |
OLLAMA_MODELS | Alternativer Speicherort für Modelle |
OLLAMA_NUM_PARALLEL | Anzahl paralleler Anfragen |
3.3 Sicherheitsaspekte
- Lokaler Betrieb: Standardmäßig lauscht Ollama nur auf 127.0.0.1 – nur lokale Prozesse haben Zugriff.
- Firewall: Im Firmennetzwerk muss Port 11434 durch Firewall-Regeln auf autorisierte Clients beschränkt werden.
- Modellquellen: Nur Modelle aus dem offiziellen Ollama-Repository (ollama.com/library) verwenden.
- Prompt-Inhalte: Keine Zugangsdaten, private Schlüssel oder unnötige personenbezogene Daten in Prompts aufnehmen.
Wichtig: Lokale KI ersetzt keine Sicherheitsarchitektur. Rechteverwaltung, Netzwerksicherheit, Zugriffsprotokollierung und Backups sind weiterhin eigenverantwortlich zu organisieren.
3.4 Alternativen zu Ollama
- LM Studio – Einfache GUI, gut für Einsteiger, etwas schwergewichtiger.
- LocalAI – Flexible OpenAI-kompatible API, komplexer in der Einrichtung.
- Jan – Moderne Desktop-App mit lokaler KI und API-Unterstützung.
- Text Generation WebUI – Sehr flexibel, eher für erfahrene Nutzer.
- Open WebUI – Grafische Oberfläche, die typischerweise auf Ollama läuft.
4 Gemma 4
Gemma ist eine Familie lokaler KI-Sprachmodelle von Google. Die Modelle wurden mit dem Ziel entwickelt, effizient auf Consumer-Hardware zu laufen und gleichzeitig für typische Entwickleraufgaben brauchbare Ergebnisse zu liefern.
Gemma-Modelle sind als Open-Weight-Modelle verfügbar: Die Gewichte (die eigentlichen Modelldaten) können heruntergeladen und lokal betrieben werden.
Hinweis: Nicht zu verwechseln mit Googles Cloud-Modellen (Gemini). Gemma ist die lokale Variante für den Eigenbetrieb.
4.1 Einsatzbereiche
Gut geeignet:
- Swift-, Python- oder JavaScript-Code analysieren
- Fehler im Code suchen und erklären
- Dokumentationen und Kommentare erzeugen
- Übersetzungen (Code-Kommentare, Dokumentationen)
- Refactoring-Vorschläge erstellen
- Unit-Test-Entwürfe generieren
- Crash-Logs oder Stack Traces einordnen
- Texte zusammenfassen
Weniger geeignet:
- Sehr große Multi-Projekt-Analysen (eingeschränktes Kontextfenster)
- Tiefes Verständnis komplexer, verteilter Architekturen
- Autonome, mehrstufige Agenten-Workflows
- Aufgaben, die aktuelle Informationen aus dem Web erfordern
Grenzen und Risiken: Wie alle KI-Sprachmodelle kann Gemma 4 Aussagen erzeugen, die plausibel klingen, aber sachlich falsch sind (Halluzinationen). Security-Reviews, Architekturentscheidungen und Datenschutzprüfungen müssen weiterhin von Menschen vorgenommen werden.
4.2 Modellgrößen & Hardware-Anforderungen
| Größe | Beispiel | Eigenschaften |
|---|---|---|
| Klein (2B–4B) | gemma:2b | Schnell, wenig RAM, einfachere Aufgaben |
| Mittel (7B–9B) | gemma:9b | Ausgewogen, gute Alltagstauglichkeit |
| Groß (27B) | gemma:27b | Bessere Qualität, hoher Speicherbedarf |
| Modellgröße | Empfohlener RAM |
|---|---|
| Kleine Modelle (bis 4B) | 16 GB |
| Mittlere Modelle (7B–9B) | 32 GB |
| Große Modelle (27B) | 64 GB oder mehr |
Apple Silicon: Macs mit M-Prozessoren eignen sich besonders gut für lokale KI, weil RAM und GPU-Speicher geteilt werden (Unified Memory). Ein Mac mit 64 GB RAM kann ein 27B-Modell vollständig im Speicher halten, ohne zwischen RAM und VRAM wechseln zu müssen.
4.3 Relative Leistung
| Modellgröße | Relative Qualität (Schätzung) |
|---|---|
| Kleine Gemma-Modelle (2B–4B) | 35–50 % eines modernen Cloud-Modells |
| Mittlere Gemma-Modelle (7B–9B) | 50–70 % |
| Große Gemma-Modelle (27B) | 70–85 % |
Diese Einschätzung gilt für typische Entwickleraufgaben wie Code-Analyse, Dokumentation und einfaches Refactoring. Bei sehr komplexen Aufgaben fällt die Lücke größer aus.
5 Weitere Modelle in Ollama
Ollama unterstützt neben Gemma viele weitere Modelle. Eine aktuelle Liste findet sich unter ollama.com/library.
| Modell | Herkunft | Besonderheiten |
|---|---|---|
| Llama 3 / Llama 3.1 | Meta | Weit verbreitet, gut dokumentiert |
| Qwen | Alibaba | Stärken bei mehrsprachigen Aufgaben |
| Mistral / Mixtral | Mistral AI | Effizient, gute Instruction-Following-Qualität |
| DeepSeek | DeepSeek | Stärken bei Code-Aufgaben |
| Phi-3 / Phi-4 | Microsoft | Kleine, effiziente Modelle |
Tool-Calling: Nicht jedes Modell unterstützt Tool-Calling zuverlässig. Tool-Calling bedeutet, dass das Modell strukturiert Werkzeugaufrufe zurückgeben kann (Dateilesen, Befehlsausführung). Ohne funktionierendes Tool-Calling arbeiten automatisierte Systeme unzuverlässig. Vor dem Einsatz in einem Tool-System prüfen, ob das gewählte Modell Tool-Calling unterstützt.
6 Die HTTP-API
Die HTTP-API ist die eigentliche Grundlage von Ollama. Alle weiteren Werkzeuge – einschließlich OpenCode – kommunizieren intern über diese Schnittstelle. Wer die API versteht, versteht das System.
Basis-URL: http://localhost:11434
Ollama lauscht standardmäßig nur auf localhost – nur lokale Prozesse haben Zugriff.
| Endpunkt | Methode | Zweck |
|---|---|---|
/api/generate | POST | Einfache Text-Generierung (Prompt → Antwort) |
/api/chat | POST | Chat-Konversation mit Nachrichten-Array |
/api/tags | GET | Installierte Modelle auflisten |
/api/show | POST | Informationen zu einem Modell abrufen |
/api/pull | POST | Modell herunterladen |
/api/delete | DELETE | Modell entfernen |
/v1/chat/completions | POST | OpenAI-kompatibler Endpunkt |
6.1 Endpunkt: /api/generate
Der einfachste Einstieg. Sendet einen Prompt und empfängt eine Antwort.
curl http://localhost:11434/api/generate \
-H "Content-Type: application/json" \
-d '{
"model": "gemma4",
"prompt": "Was ist das Repository-Pattern in Swift?",
"stream": false
}'Wichtige Felder in der Antwort:
| Feld | Bedeutung |
|---|---|
response | Die eigentliche Antwort des Modells |
done | true wenn die Generierung abgeschlossen ist |
total_duration | Gesamtzeit in Nanosekunden |
eval_count | Anzahl generierter Tokens |
Mit "stream": true liefert Ollama die Antwort als Datenstrom (NDJSON). Wann Streaming verwenden:
- In interaktiven UIs, die Text schrittweise anzeigen sollen
- Bei langen Antworten, um die Wartezeit zu überbrücken
6.2 Endpunkt: /api/chat
Für Konversationen mit mehreren Nachrichten. Das Modell erhält den bisherigen Gesprächsverlauf.
curl http://localhost:11434/api/chat \
-H "Content-Type: application/json" \
-d '{
"model": "gemma4",
"messages": [
{
"role": "system",
"content": "Du bist ein erfahrener Swift-Entwickler."
},
{
"role": "user",
"content": "Welche Probleme kann Force Unwrapping in Swift verursachen?"
}
],
"stream": false
}'| Rolle | Bedeutung |
|---|---|
system | Anweisung an das Modell (Verhalten, Kontext, Einschränkungen) |
user | Nachricht des Nutzers |
assistant | Frühere Antworten des Modells (für Gesprächsverlauf) |
6.3 OpenAI-kompatibler Endpunkt
Ollama bietet eine OpenAI-kompatible API-Schnittstelle. Werkzeuge und Bibliotheken, die ursprünglich für OpenAI entwickelt wurden, funktionieren oft unverändert mit Ollama. OpenCode nutzt intern diesen Endpunkt.
curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ollama" \
-d '{
"model": "gemma4",
"messages": [
{"role": "system", "content": "You are a Swift expert."},
{"role": "user", "content": "Explain @MainActor in one paragraph."}
],
"stream": false
}'Hinweis: Bei Ollama wird der Authorization-Token nicht geprüft. Der Header muss aber vorhanden sein, wenn Bibliotheken ihn erwarten. Jeder Wert funktioniert.
6.4 Zusätzliche Optionen & häufige Fehler
{
"model": "gemma4",
"prompt": "...",
"stream": false,
"options": {
"temperature": 0.2,
"num_ctx": 8192,
"num_predict": 2048,
"top_p": 0.9
}
}| Option | Bedeutung | Empfehlung |
|---|---|---|
temperature | Kreativität der Antworten (0 = deterministisch, 1 = kreativ) | 0.1–0.3 für Code-Aufgaben |
num_ctx | Kontextfenstergröße in Tokens | Je nach Modell bis 8192 oder mehr |
num_predict | Maximale Anzahl generierter Tokens | Je nach Aufgabe anpassen |
top_p | Nucleus-Sampling-Parameter | Meist Standard belassen |
7 Eigene Anwendungen entwickeln
Eigene Anwendungen sprechen Ollama direkt über HTTP an. Es wird keine besondere Bibliothek benötigt – eine einfache HTTP-Anfrage mit JSON-Body reicht aus.
Die Anwendung ist selbst verantwortlich dafür:
- welche Dateien gelesen werden
- welcher Kontext für den Prompt aufgebaut wird
- wie die Antwort verarbeitet und dargestellt wird
- welche Dateien geändert werden dürfen
7.1 Beispiel in Swift
import Foundation
// MARK: - Datenmodelle
struct OllamaGenerateRequest: Encodable {
let model: String
let prompt: String
let stream: Bool
let options: OllamaOptions?
}
struct OllamaOptions: Encodable {
let temperature: Double
let numCtx: Int
enum CodingKeys: String, CodingKey {
case temperature
case numCtx = "num_ctx"
}
}
struct OllamaGenerateResponse: Decodable {
let model: String
let response: String
let done: Bool
}
// MARK: - Ollama-Client
struct OllamaClient {
let baseURL: URL
let model: String
private let session: URLSession
init(
baseURL: URL = URL(string: "http://localhost:11434")!,
model: String = "gemma4"
) {
self.baseURL = baseURL
self.model = model
let config = URLSessionConfiguration.default
config.timeoutIntervalForRequest = 300 // 5 Minuten
self.session = URLSession(configuration: config)
}
func generate(prompt: String) async throws -> String {
let endpoint = baseURL.appendingPathComponent("api/generate")
let body = OllamaGenerateRequest(
model: model,
prompt: prompt,
stream: false,
options: OllamaOptions(temperature: 0.2, numCtx: 8192)
)
var request = URLRequest(url: endpoint)
request.httpMethod = "POST"
request.setValue("application/json", forHTTPHeaderField: "Content-Type")
request.httpBody = try JSONEncoder().encode(body)
let (data, response) = try await session.data(for: request)
guard let http = response as? HTTPURLResponse,
(200...299).contains(http.statusCode) else {
throw URLError(.badServerResponse)
}
let decoded = try JSONDecoder().decode(OllamaGenerateResponse.self, from: data)
return decoded.response
}
}7.2 Praxisbeispiel: XcodeX CLI
Ein konkretes Beispiel für eigene KI-Integration ist XcodeX CLI – ein Tool, das den Build-, Test- und Deploy-Prozess unter Xcode optimiert. Es ermöglicht:
- Apps bauen und auf mehrere Testgeräte verteilen
- Automatisierte Unit-Tests mit verschiedenen Konfigurationen ausführen
- Unabhängig von Xcode arbeiten, da in einem separaten DerivedData gebaut wird
Im nächsten Release wird eine lokale KI eingebunden, um den Entwickler direkt im Workflow zu unterstützen.
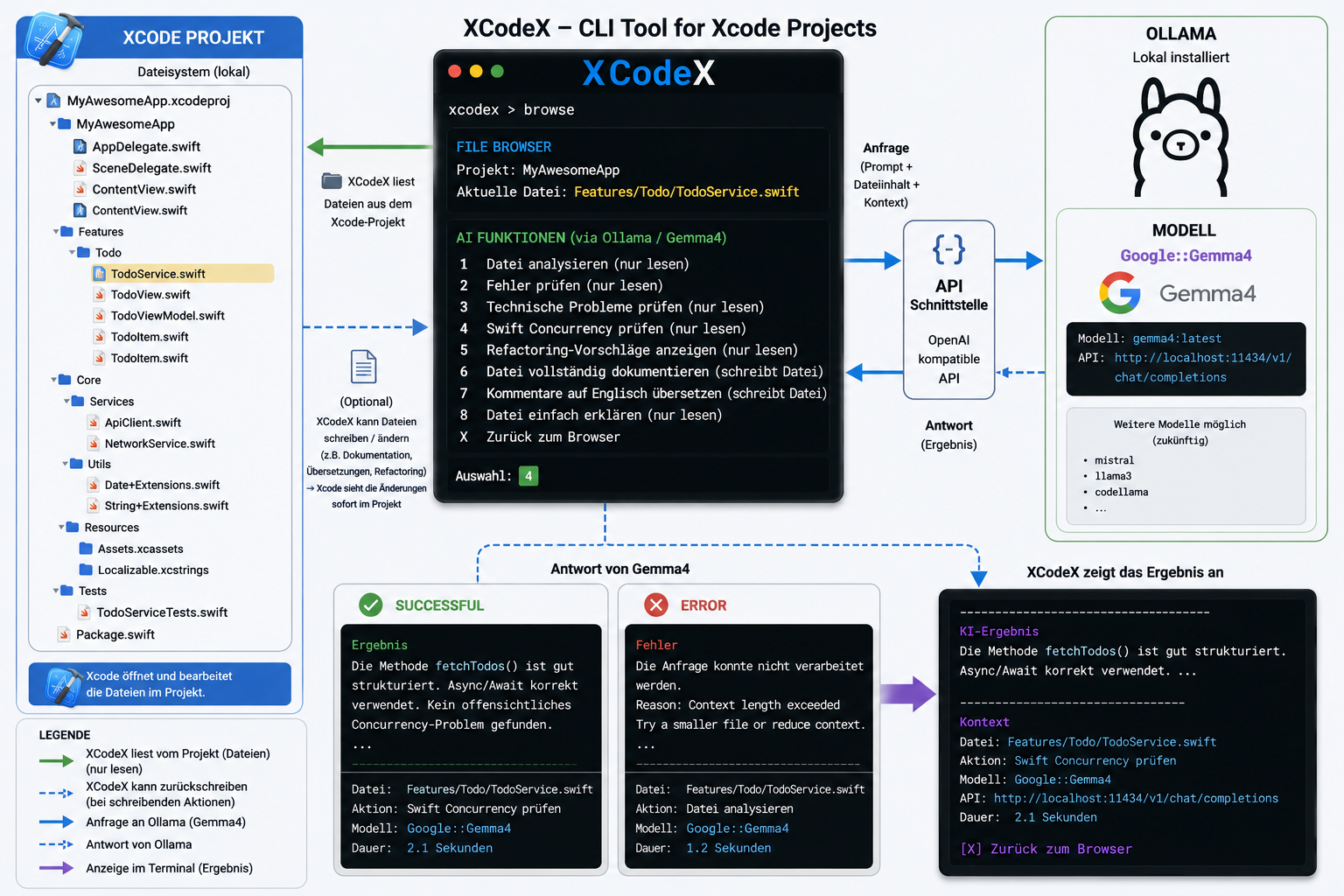
XcodeX mit Ollama und Gemma 4 – lokale KI-Integration im Entwicklungsworkflow
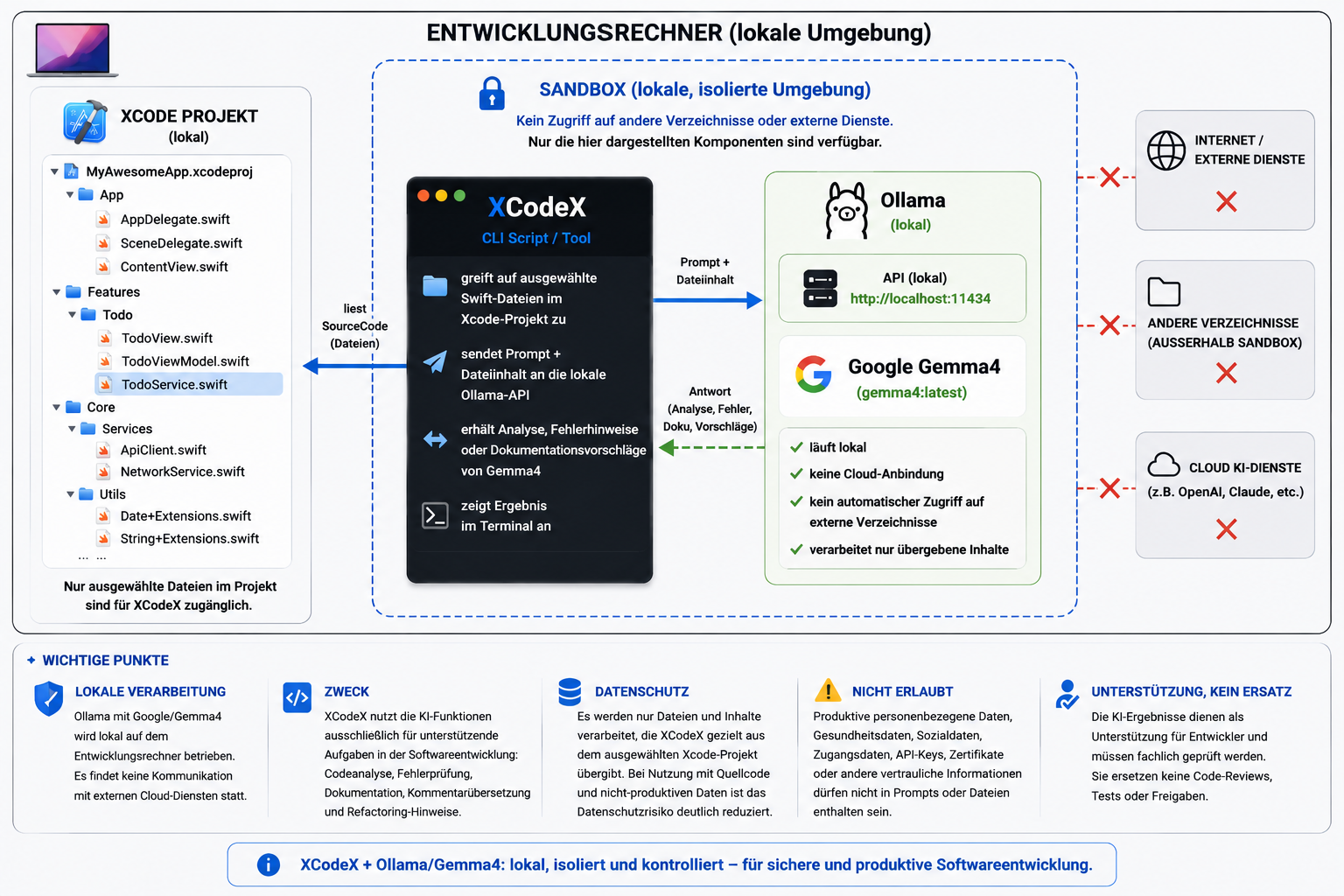
XcodeX mit Ollama und Gemma 4 – weitere Ansicht
Besonders interessant für Firmen mit Datenschutzanforderungen: Da die KI-Integration auf Ollama basiert, verlassen keine Daten die eigene Infrastruktur — die Verarbeitung findet vollständig lokal statt. Weitere Informationen: xcodexcli.com
8 OpenCode
OpenCode ist ein lokales Tool-System für KI-gestützte Softwareentwicklung. Die Idee orientiert sich an Werkzeugen wie Claude Code: Eine KI analysiert Code, schlägt Änderungen vor und kann Dateien direkt bearbeiten. Im Unterschied zu Cloud-basierten Lösungen kann OpenCode mit lokalen Modellen über Ollama betrieben werden.
| Begriff | Bedeutung |
|---|---|
| KI-Modell (z. B. Gemma 4) | Verarbeitet Text, erzeugt Antworten, hat keinen direkten Systemzugriff |
| Tool-System (z. B. OpenCode) | Führt lokale Aktionen aus: Dateien lesen/ändern, Befehle ausführen |
| Laufzeit (z. B. Ollama) | Startet und betreibt das Modell, stellt die API bereit |
OpenCode nutzt intern den OpenAI-kompatiblen Endpunkt von Ollama: http://localhost:11434/v1
8.1 Installation
Variante 1 – Installationsskript:
curl -fsSL https://opencode.ai/install | bash
# Prüfen ob der Befehl gefunden wird
which opencode
# Falls nicht: Pfad suchen
find ~ -name "opencode" -type f 2>/dev/null
# Pfad zur Shell-Konfiguration hinzufügen (zsh)
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.zshrc
source ~/.zshrcVariante 2 – npm:
brew install node
npm install -g opencode-ai
# Version prüfen
opencode --versionHinweis: Installationsmethoden und verfügbare Versionen ändern sich. Die aktuelle Installationsanleitung sollte direkt von der offiziellen OpenCode-Dokumentation bezogen werden. Skripte aus dem Internet vor der Ausführung prüfen.
8.2 Konfiguration (opencode.json)
Die Konfigurationsdatei liegt unter ~/.config/opencode/opencode.json:
mkdir -p ~/.config/opencode
nano ~/.config/opencode/opencode.jsonBeispielkonfiguration für Ollama mit Gemma 4:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"ollama": {
"npm": "@ai-sdk/openai-compatible",
"options": {
"baseURL": "http://localhost:11434/v1"
},
"models": {
"gemma4": {
"name": "Gemma 4"
}
}
}
},
"model": "ollama/gemma4",
"permission": {
"bash": "allow",
"read": "allow",
"glob": "allow",
"grep": "allow",
"edit": "ask",
"write": "ask",
"task": "deny",
"webfetch": "deny"
}
}8.3 Rechteverwaltung
| Wert | Bedeutung |
|---|---|
"allow" | Wird automatisch ausgeführt, ohne Nachfrage |
"ask" | OpenCode fragt den Nutzer vor jeder Aktion |
"deny" | Wird grundsätzlich nicht erlaubt |
Empfehlung für produktive Nutzung: bash: "ask", webfetch: "deny", task: "deny". Die Rechte sollten so restriktiv wie möglich gesetzt werden, besonders wenn OpenCode auf einem Rechner mit Zugang zu internen Systemen läuft.
OpenCode starten:
cd /pfad/zu/deinem/projekt
opencode9 Claude Code im Vergleich
Dieser Abschnitt erklärt kurz, was Cloud-basierte Werkzeuge wie Claude Code zusätzlich bieten – nicht als Empfehlung, sondern als sachlicher Vergleich.
| Merkmal | Ollama + eigene Integration | OpenCode + Ollama | Claude Code |
|---|---|---|---|
| Datenlage | Vollständig lokal | Vollständig lokal | Cloud (Anthropic) |
| Modellqualität | Abhängig vom Modell | Abhängig vom Modell | Hoch (Cloud-Modell) |
| Tool-System | Selbst entwickeln | Vorhanden | Vorhanden |
| Kontextverwaltung | Selbst entwickeln | Vorhanden | Automatisch |
| Datenschutz | Vollständig kontrollierbar | Vollständig kontrollierbar | Anbieterabhängig |
| Entwicklungsaufwand | Hoch | Mittel | Gering |
| Laufende Kosten | Hardware | Hardware | Pro Token / Abo |
| Modellstärke | 50–85 % (Schätzung) | 50–85 % (Schätzung) | Referenz |
10 Fehlerdiagnose
Ollama antwortet nicht
curl: (7) Failed to connect to localhost port 11434: Connection refusedLösung: Ollama-Server starten:
ollama serve
# Prüfen ob der Prozess läuft
lsof -i :11434Falscher Modellname
{"error":"model \"gemma_4\" not found, try pulling it first"}Lösung: Installierte Modelle prüfen und exakten Namen verwenden:
ollama listZu wenig RAM
Symptome: Extrem langsame Antworten, System reagiert kaum noch, Abstürze. Lösung:
- Kleineres Modell wählen
- Andere Anwendungen schließen
ollama rmfür nicht benötigte Modelle aufrufen
# RAM-Auslastung beobachten (macOS)
top -o MEMOpenCode findet Ollama nicht
# baseURL in der Konfiguration prüfen:
"baseURL": "http://localhost:11434/v1"
# Endpunkt testen:
curl http://localhost:11434/v1/models \
-H "Authorization: Bearer ollama"Timeout bei langen Anfragen
Ursache: Die Standard-Timeout-Einstellung des HTTP-Clients ist zu kurz für große Modelle oder lange Prompts. Lösung: Timeout auf mindestens 5 Minuten setzen, bei sehr großen Kontexten 10 Minuten.
Temperaturentwicklung auf MacBooks
Intensive KI-Berechnungen können MacBooks stark aufheizen. Für längere Sessions den Mac auf einer Oberfläche mit guter Belüftung betreiben. Große Modelle nicht gleichzeitig mehrfach starten.
11 Empfehlungen aus der Praxis
Einstieg
- Ollama installieren und mit
ollama servestarten - Ein kleines Modell (
gemma4in der Standard-Größe) herunterladen - Erst mit
ollama run gemma4im Terminal testen - Dann einfache
curl-Aufrufe ausprobieren - Erst danach eigene Integration oder OpenCode einrichten
Modellauswahl
- Für einfache Aufgaben und schnelles Testen: kleines Modell wählen
- Für produktive Nutzung: mittleres Modell als Kompromiss aus Qualität und Geschwindigkeit
- Große Modelle nur wenn die Hardware ausreichend RAM hat
- Verschiedene Modelle für verschiedene Aufgabentypen testen
Sicherheit in Firmenumgebungen
- Ollama nur auf localhost betreiben, solange kein Netzwerkbetrieb benötigt wird
- Wenn Netzwerkbetrieb: Firewall-Regeln definieren, Zugriff auf autorisierte Rechner beschränken
- Nur Modelle aus vertrauenswürdigen Quellen (offizielle Ollama-Registry) einsetzen
- Keine Zugangsdaten, API-Keys oder private Schlüssel in Prompts aufnehmen
- OpenCode-Berechtigungen so restriktiv wie möglich konfigurieren
Prompt-Qualität
- Kurze, präzise Prompts liefern oft bessere Ergebnisse als lange, vage Beschreibungen
- System-Prompt für Kontext und Einschränkungen nutzen
- Ausgabeformat im Prompt definieren (z. B. „Antworte nur mit Swift-Code, keine Erklärungen")
- KI-Ausgaben immer prüfen, nie blind übernehmen
Erwartungsmanagement
Lokale KI mit Gemma 4 ist ein nützliches Werkzeug für Routineaufgaben wie Code-Dokumentation, einfache Fehlersuche und Übersetzungen. Für komplexe architektonische Entscheidungen, tiefe Sicherheitsanalysen oder sehr große Codebasen sind aktuelle lokale Modelle noch deutlich schwächer als Cloud-Lösungen.
Kernaussage: Der Hauptvorteil lokaler KI liegt nicht in der Modellqualität, sondern in der Datensouveränität: Die Daten bleiben auf der eigenen Infrastruktur.